
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 언리얼5
- 리팩터링
- 언리얼 5
- 112일선
- GenAI
- 스즈메의 문단속
- 스포일러 주의
- 448일선
- 주식단테
- 이득우의 언리얼 프로그래밍1
- 산토리 하이볼
- 주식
- 1일차
- 상계9동
- 리팩터링 3장
- 2023 구글 클라우드
- 작계훈련
- 2023 게이밍 인 구글 클라우드
- URP
- 224일선
- 이득우의 언리얼 프로그래밍 1
- 구글 컨퍼런스
- unity
- 2023 Gaming
- shader
- 전주비빔 라이스 버거
- JavaScript
- 공부
- 2023 게이밍
- 리팩터링 4장
- Today
- Total
개발 이야기 안하는 개발자
전문가를 위한 C++20 _ 3 (전문가답게 C++ 코딩하기) 본문
7. 메모리 관리
int i { 7 };로컬 변수 i는 자동 변수라 부르며 스택에 저장된다.
변수가 선언된 스코프를 벗어나면 자동으로 메모리가 해제된다.
new와 delete
int* ptr { nullptr };
ptr = new int;new 키워드로 메모리를 할당하면 프리스토어에 메모리가 할당된다.
new로 할당한 메모리는 delete 키워드로 해제한다.
만약, 포인터를 담았던 변수가 스코프를 벗어나면 할당한 메모리에 접근할 수 없게 되고 이를 "미아가 된다" 라고 표현한다.
이를 메모리 누수(메모리 릭)이라 부른다.
new가 실패하는 경우는 해당 메모리 만큼 가지고 있지 않을때 그런다.
예외처리로 막으면 되는데 이때 nothrow를 사용하면 예외처리가 가능하다.
int* ptr { new(nothrow) int };
배열에서도 마찬가지로 new를 사용하지 않는다면 스택에 할당된다.
int myArray[5]; //스택에 5개 저장됨
int* newMyArray { new int[] {1,2,3,4,5} }; //new로 할당된 각각 1,2,3,4,5는 프리스토어에 저장됨.
Simple* mySimplyArray { new Simple[4] };
delete [] mySimpleArray;
mySimpleArray = nullptr;
newMyArray는 스택에 저장되어 프리스토어에 저장된 int 배열 0번을 가르키게 된다.
댕글링 포인터 : 이미 삭제한 데이터에 참조가 끊기지 않고 계속 참조하며 사용할때 생기는 문제.
malloc
c에서 많이 사용하며, 인수로 지정한 바이트 수 만큼 메모리를 할당하는 키워드이다.
C++에서는 malloc 보다는 new를 쓰는게 좋은데, new는 단순한 메모리 할당에서 그치지 않고,객체까지 만들기 때문이다.
스마트 포인터
1. unique_ptr : 단독 소유권을 제공
제거되거나 리셋되면 포인터가 가르키던 리소스가 자동을 해제된다.
기존
Simple* mySimplePtr { new Simple{} };
mySimplePtr->go();
delete mySimplePtr;
스마트 포인터
auto mySimplePtr { make_unique<Simple>() };
mySimplePtr->go();스마트 포인터는 사용후 스코프를 벗어나면 또는 익셉션이 발생하면 소멸자가 자동으로 호출되서 해제된다.
만약 생성자에 매개변수가 있다면 (Simple(int, int) 인 경우) 소괄호 사이에 지저애 주면 된다.(make_unique<Simple>(1,2);)
unique_ptr<Simple> mySimplePtr { new Simple{} }:위와 같이 초기화 할 수도 있다.
단, unique_ptr에서는 CTAD를 사용할 수 없기때문에 템플릿 타입을 생략해서는 안된다.
get()을 통해 내부 포인터에 접근이 가능하다.
reset()를 활용하여 unique_ptr의 내부 데이터를 해제하고 필요하면 다른 포인터로 변경할 수 있다.
mySimpleSmartPtr.reset();
mySImpleSmartPtr.reset(new Simple{});
release()를 통해서 내부 포인터의 관계를 끊을 수 있다. (소유권을 해제한다)
unique_ptr은 단독 소유권이기 때문에 복사를 할 수 없다.
하지만 move를 통해 이동은 가능하다.
2. shared_ptr : 소유권을 공유한다.
스마트 포인터
auto mySimplePtr { make_shared<Simple>() };
mySimplePtr->go();기능적으로 unique와 대부분 일치하다.
shared는 동일한 리소스를 가르키는 여러개의 인스턴스가 해당 리로스를 해제할 시점을 알아내기 위해 레퍼런스 카운팅이란 기법으로 작동한다.
이 레퍼런스 카운팅으로 모두 해제가 된 시점에 해제가 되고, unique와 다르게 release()를 지운하지 않는다.
공유하기 때문이다.
use_count()를 통해 현재 동일한 리소스를 공유하는 shared_ptr의 개수를 알아낼 수 있다.
3. weak_ptr : shared_ptr이 관리하는 리소스에 대한 레퍼런스를 가질 수 있다.
weak는 shared와 같이 레퍼런스를 공유받을 수 있지만, shared의 count는 증가시키지 않으며 분리되어 있는 포인터이다.
스마트 포인터
auto sharedPtr {make_shared<simple>() };
weak_ptr<simple> weakSimple {sharedPtr};위와 같은 방식으로 만들 수 있다.
이때, weak_ptr은 lock() 을 통해서 리소스를 받아온다.
사용하는 도중에 shared가 reset으로 데이터가 해제될때 (weak은 카운팅 안되기 때문에 shared 모두 해제되면 해제됨)
weak는 같이 해제된다.
enable_shared_from_this
Simple* s = new Simple{};
shared_ptr<Simple> s1 { s };
shared_ptr<Simple> s2 { s };
s1, s2가 해제할때 에러 발생 ==> 같은 s를 해제하려고 하기 때문.
enable_shared_from_this 는 위와 같은 상황을 해결하고자 나왔다.
결국 shared_ptr을 새로 만든 내용이기 때문에 s를 shared하는게 아니고 s를 shared하는 2개의 shared_ptr을 만들었기 때문이다.
이를 위해 Simple 클래스에 enable_shared_from_this를 상속받고, 복사하는 메소드를 하나 제작해야 한다.
class Simple : public enable_shared_from_this<Simple>
{
public :
shared_ptr<Simple> getPointer()
{
return shared_from_this();
}
};
이후 s2를 제작할땐 auto s2 { s1->getPointer()}; 라고 정의해야 같은 shared를 공유하게 되는 것이다.
이를 확인하기 위해선 use_count()를 사용해서 얼마나 공유하고 있는지 확인해 보면 된다.
위 내용은 weak도 동일하다. (shared라고 적힌 부분은 weak로 변경하면 된다)
8.클래스와 객체 이해
클래스 생성자에 있어서 디폴트 생성자를 만들 수 있다.
이때, 명시적으로 디폴트 생성자라고 표현할 수 있다.
class SpreadsheetCell
{
public :
SpreadsheetCell() = default;
SpreadsheetCell(double initVal);
...
}같은 방식으로 명시적으로 삭제 생성자를 지원한다. ( default위치에 delete를 넣으면 된다)
복제 생성자
class SpreadsheetCell
{
public :
SpreadsheetCell(const SpreadsheetCell& src);
}
SpreadsheetCell::SPreadsheetCell(const SpreadsheetCell& src) : m_value { src.m_value}
{
}
변수들을 모두 가져오지 않고 m_value를 통해 모든 데이터를 복사할 수 있다.
9. 클래스와 객체 완전 정복
프렌드
다른 클래스의 private이나 protected에 접근이 가능하다.
class Foo
{
friend class Bar;
...
}
복제 대입 연산자
class SpreadsheetCell
{
public :
SpreadsheetCell& operator=(const SpreadsheetCell& src);
}
SpreadsheetCell::SpreadsheetCell& operator=(const SpreadsheetCell& src);
{
//자신인가?
if(this == &src)
{
return *this;
}
//1. 기존 this의 메모리 해제
//2. 기존 this의 메모리를 새로 할당(src의 데이터로 복사)
}
우측값 레퍼런스
C++에선 좌측값(lvalue)와 우측값(rvalue)가 있다.
예를 들러 int a { 8 }; 일때, a가 좌측값이고 8이 우측값이다.
함수의 매개변수에 &&를 붙여서 우측값 레퍼런스로 만들 수 있다.
void TestFunc(string& mes) {} //좌측값 레퍼런스 매개변수
void TestFunc(string&& mes) {} //우측값 레퍼런스 매개변수
string a {"h"};
TestFunc(a); //좌측값으로 호출함.
string b {"b"};
TestFunc(a + b); //우측값으로 호출함.
TestFunc("hb"); //우측값으로 호출함.
b = a; //이때, b와 a는 모두 좌측값이다.
위 코드에서 a + b는 표현식의 결과로 생성되는 임시 객체가 좌측값이 아니기 때문에 우측값 레퍼런스 버전으로 호출된다.
이동 생성자와 이동 대입 연산자
void Spreadsheet::moveFrom(Spreadsheet& src) noexcept
{
//1. 데이터 얕은 복제
//2. 원본 데이터 리셋 (src 데이터)
}
Spreadsheet::Spreadsheet(Spreadsheet&& src) noexcept
{
moveFrom(src);
}
Spreadsheet& Spreadsheet::operator=(Spreadsheet&& rhs) noexcept
{
// 자신 데이터인지 확인
// 기존 데이터 삭제
moveFrom(rhs);
return *this;
}
같은 방식이지만 move를 사용해도 된다.
Spreadsheet sheet1;
Spreadsheet sheet2 = std::move(sheet1);move는 기존에 있던 sheet1 데이터를 sheet2로 가지고 오는 것으로 sheet1은 초기화 된다.
이렇게 move를 사용함으로서 컴파일러에게 sheet1이 오른값이라고 알려주는 행위가 된다.
std::exchange()
int a {11};
int b {22};
//출력 : a는 11 , b 는 22
int returnedValue { exchange(a, b) } ;
//출력 : a는 22 , b 는 22 , returnedValue 는 11exchange는 기존 값을 새 값으로 교체한 후 기존 값을 리턴한다.
이는 이동 대입 연산자를 구현할때 유용하다.
RVO : 리턴 값 최적화
A makeA(string name)
{
return A(name);
}
NRVO : 네임드 리턴 값 최적화
A makeA(string name)
{
A a(name);
return a;
}
RVO가 NRVO보다 더 보기좋고 속도도 빠르다.
하지만 Build 이후 release를 보게 되면 둘의 속도가 비슷한걸 볼수 있는데, 이는 컴파일에서 최적화 과정을 걸쳐 스스로 빠른 방법으로 변경했기 때문이다.
5의 규칙 (Rule of Five)
클래스에 소멸자, 복제 생성자, 이동 생성자, 복제 대입 연산자, 이동 대입 연산자등과 같은 특수 멤버 함수를 하나 이상 선언했다면 일반적으로 모두 선언해야 한다.
영의 규칙 (Rule of Zero)
5의 규칙함수를 구현할 필요 없이 클래스를 디자인해야 한다. (모던 C++에선 영의 규칙을 따른다) 메모리를 동적으로 할당하지 말고 표준 라이브러리 컨테이너와 같은 최신 구문을 활용해야 한다. 예를 들어 Spreadsheet클래스에서 SpreadsheetCell** 데이터 멤버 대신 vector<vector<SpreadsheetCell>>을 사용한다. 벡터는 메모리를 자동으로 관리하기 때문에 앞서 언급한 다섯 가지 특수 멤버 함수가 필요없다.
10. 상속 활용하기
final 키워드
더이상 상속이 불가능 하다.
class Base fianl {};
abstract를 사용하려면 메서드 뒤에 = 0 울 붙이면 된다.
LSP 리스코프 치환 원칙 : 자식은 언제나 부모 타입으로 교체할 수 있어야 한다.
const_cast : 상수(const)를 제거하는 것에 사용
static_cast : 기본 자료형의 형변환과 다운 캐스트에서 사용
reinterpret_cast : 서로 관련없는 레퍼런스끼리 형변환이 가능하다 (포인터끼리도 가능)
dynamic_cast : 런타임에 타입 검사를 수행하고, 같은 계층의 포인터 형 변환
bit_cast : reinterpret_cast와 비슷함. 객체를 새로 만들어서 원본 객체에 있는 비트를 새객체로 복제한다.
11. C++의 까다롭고 유별난 부분
모듈
익스포트한 모든 대상을 모듈 인터페이스라 부른다.
콜론(:)으로 모듈을 구성하는 다양한 파티션으로 나눠서 정의가 가능하다.
export module datamodel:address;
export namespace DataModel
{
class Address
{
public :
Address();
...
};
}
12. 템플릿으로 제네릭 코드 만들기
템플릿
값에 대한 매개변수화를 확장해서 타입에 대해서도 매개변수화할 수 있게 만드는것.
template <typename T>
class Test
{
public :
optional<T>& something();
...
}첫줄에 나온 T로 지정한 특정한 타입에 적용할수 있는 템플릿이라고 선언한다.
template <typename T>
Test<T>::Test() {};
template <typename T>
optional<T>& Test<T>::something() { ... };메소드인 경우에도 붙여야 한다.
Test<SpreadsheetCell> myTest;
SPreadsheetCell myCell {1.235};
myTest.something() = myCell;제네릭 T엔 다양한 타입을 넣을 수 있다.
컴파일러는 템플릿 메서드 정의 코드를 발견하면 컴파일하지 않고 문법검사만 진행한다.
비타입 템플릿
int나 포인터처럼 흔히 사용하는 종류의 매개변수 (정수 계열, 열거, 포인터, 레퍼런스 등만 사용가능)
export template <typename T, size_t W , size_t H>
class Test
{
...
}
//사용
Text<int, 10, 10> myTest;
...
템플릿은 디폴트값을 줄 수 있다.
export template <typename T = int, size_t W = 10 , size_t H = 9>
class Test
{
...
}
//사용
Test<> myTest1;
Test<double> myTest2;
Test<int, 5> myTest3;
Test<int, 5, 1> myTest4;
Test myErrorTest; // 에러
...
13. C++ I/O 심층 분석
cin : 입력 스트림. '입력 콘솔'에 들어온 데이터를 읽는다.
cout : 버퍼를 사용하는 출력 스트림. 데이터를 '출력 콘솔'에 쓴다.
cerr : 버퍼를 사용하지 않는 출력 스트림. 데이터를 '에러 콘솔'에 쓴다.
clog : 버퍼를 사용하는 cerr
이때, c는 character(문자)를 의미한다.
Flush() : 들어온 데이터를 곧바로 쓰지 않고 버퍼에 잠시 쌓아두는데 flush를 통해 조건에 해당할때 버퍼를 비운다.
- endl과 같은 경곗값에 도달할때
- 스트림이 스코프를 벗어났을때
- 스트림 버퍼가 가득 찼을때
- flush()를 호출했을때
good(), bad(), fail() : 입력 출력 스트림에 대해 스트림이 정상적으로 사용할 수 있는지, 또 그 결과를 알려준다.
- good - 스트림의 상태 정보 조회 (사용 못하면 원인을 구체적으로 안알려줌)
- bad - true라면 심각한 에러가 발생했다는 뜻.
- eof - 파일의 끝에 도달하면 알려줌.
- fail - 최근 수행한 연산에 오류가 발생했다. flush 연산 이후 호출하면 flush가 성공했는지 확인할 수 있다.
이때, good 과 fail은 스트림 파일끝에 도달하면 false를 반환한다.
get() : 스트림 데이터를 저수준으로 읽는다.
string Read(istream& stream)
{
while(!stream.fail())
{
int next {stream.get()};
...
}
}
unget() : 데이터를 다시 입력 소스 방향으로 보낼수 있다. 입력 스트림을 한 문자 만큼 되돌린다. (fail()로 연산 성공 여부를 확인한다)
putback() : 입력 스트림을 한 문자만큼 되돌린다. (문자를 인수로 받는다)
peek() : get()을 호출할 때 리턴될 값을 미리 보여준다. 버퍼에서 가져와서 읽기 전에 먼저 봐야할 때 유용하다.
getline() : 한줄 끝을 나타내는 \0 (EOL)문자를 포함해서 스트림에서 데이터를 한 줄씩 읽을때 사용.
파일스트림
기본적으로 텍스트 모드로 연다 (ofstream / ifstream)
파일을 생성할때는 ios_base::binary 플래그를 지정하면 바이너리 모드로 연다.
입력과 출력 스트림 모두 seek() 과 tell()을 갖는다.
seek() : 스트림에서 커서 위치를 원하는 지점으로 옮긴다.
seekg() : 입력 스트림버전 (get)
seekp() : 출력 스트림버전 (put)
tell() : 현재 스트림의 위치를 알아낸다
tellg() : 입력 스트림버전
tellp() : 출력스트림 버전
파일 경로 (Path)
path p1 { R"(D:\test\tt)" };
14. 에러 처리
try
{...} //익셉션이 발생할 수도 있는 코드
catch(익셉션_타입1 익셉션_이름)
{...}
catch(익셉션_타입2 익셉션_이름)
{...}try 문 안에서 코드를 실행하고 예상치 못하는 예외처리를 catch문 안에서 잡아 처리하는 내용이다.
예외는 throw로 직접 예외를 발생시킬수 있다.
vector<int> readIntegerFile(string_view filename)
{
ifstream inputStream { filename.data() };
if (inputStream.fail()) {
// We failed to open the file: throw an exception.
throw 5;
}
...
}
int main()
{
...
try {
myInts = readIntegerFile(filename);
} catch (int e) {
cerr << format("Unable to open file {} (Error Code {})", filename, e) << endl;
return 1;
}
...
}
위에서는 5를 던졌기 때문에 int로 catch 했다.
하지만 다른 타입으로 던졌다면 catch할때 같은 타입이면 받을 수 있다.
catch(...) : 모든 타입에 매칭할 수 있다. ...는 모든 타입에 매칭하라는 와일드카드이다.
noexcept : 메서드 뒤에 붙으며, 해당 키워드는 어떠한 익셉션도 던지지 않는다고 선언하는 키워드이다.
만약, 익셉션이 생긴다면 프로그램을 강제로 종료한다.
void f1() noexcept {}
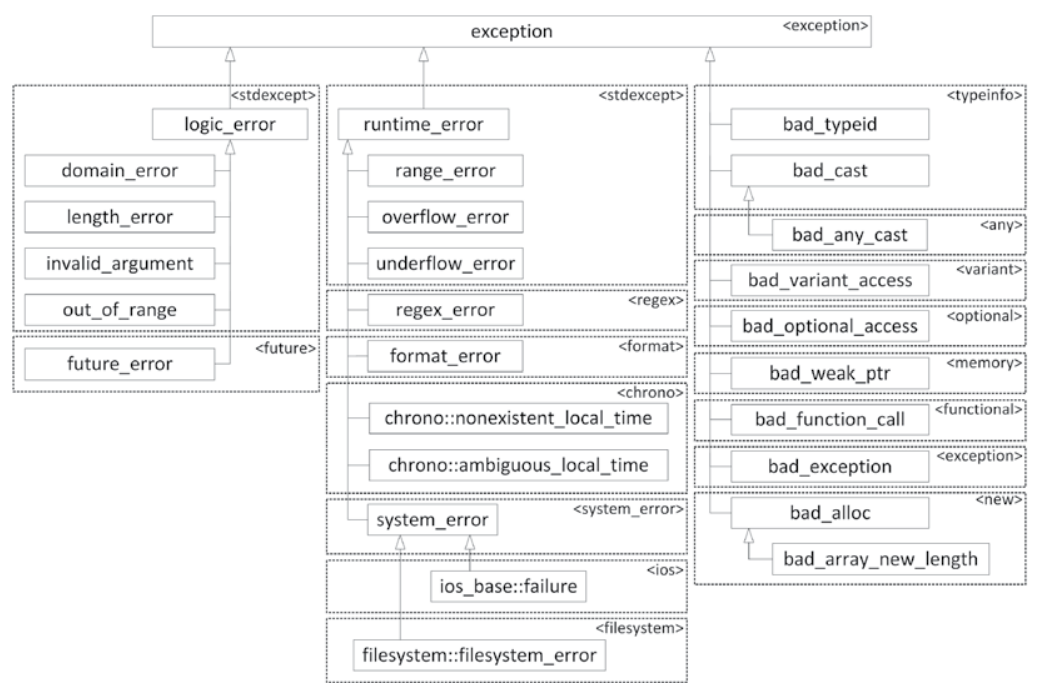
익셉션 클래스의 계층 구조
이 외에도 익셉션 클래스를 직접 정의할 수 있다.
class FileExceptionTest : public exception
{
...
}
15. C++ 연산자 오버로딩
오버로드를 진행하면서 operator&&와 operator|| 를 수정하면 의미가 달라지면서 단락평가규칙을 적용할 수 없게 되기 때문에 수정하지 않는것이 좋다.
operator, 도 안하는것이 좋다. 순차 연산자라고 불리는 < , > 는 왼쪽에서 오른쪽으로 순서가 평가되는에 이 의미가 바뀔 위험이 있기 때문이다.
16. C++ 표준 라이브러리 둘러보기
Initializer_list : 파라미터로 여러개의 인수를 받을 수 있는 방법 (C#의 Param 과 비슷함)
import <initializer_list>;
using namespace std;
int makeSum(initializer_list<int> values)
{
int total{ 0 };
for (int value : values) { total += value; }
return total;
}
int main()
{
int a{ makeSum({ 1, 2, 3 }) };
int b{ makeSum({ 10, 20, 30, 40, 50, 60 }) };
}
17. 반복자와 범위 라이브러리
반복자
컨테이너의 특정 원소를 가르키는 포인터로 생각할 수 있다.
반복자는 입력, 출력, 정방향, 양방향, 임의 접근, 연속의 6가지로 분류할 수 있다.
연속 반복자는 임의 접근 반복자이고, 임의 접근 반복자는 모두 양방향 반복자이고, 양방향 반복자는 모두 정방향 반복자이고, 정방향 반복자는 모두 입력 반복자이다.
출력 반복자의 요구사항을 만족하는 반복자를 가변 반복자라 부르고, 그렇지 않은 반복자는 상수(불변) 반복자이다.
<iteractor>에선 컨테이너의 특정 반복자를 리턴하는 다음과 같은 글로벌 비 멤버 함수도 제공한다.
begin() , end() // cbegin() , cend() // rbegin(), rend() // crbegin() , crend()
vector values{ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
for (auto iter{ cbegin(values) }; iter != cend(values); ++iter) {
cout << *iter << " ";
}
cout << endl;
메소드를 호출할때 컨테이너를 모두 넘겨주지 않고 begin과 end 반복자로 데이터를 호출 할 수 있다.
template<typename Iter>
void myPrint(Iter begin, Iter end)
{
for (auto iter{ begin }; iter != end; ++iter) {
cout << *iter << " ";
}
}
...
myPrint(cbegin(values), cend(values));
cout << endl;
18. 표준 라이브러리 컨테이너
순차 컨테이너
vector(동적 배열) , deque, list , forward_list , array
연관 컨테이너
map , multimap , set , multiset
비정렬 연관 컨테이너(해시 테이블)
unordered_map , unordered_multimap , unordered_set , unordered_multiset
컨테이너 어댑터
queue , priority_queue , stack
vector
capacity는 벡터의 용량을, size는 벡터의 크기를 뜻한다.
재할당 없이 추가할 수 있는 원소의 수는 capacity() - size() 이다.
empty()로 비어있는지 확인 할 수 있으며, 비어있다고 해도 capacity()의 리턴값은 0이 아니다.
데이터를 연속된 메모리 공간에 저장한다.
data()로 메모리 블록에 대한 포인터를 구할 수 있다.
라운드-로빈 스케줄링 알고리즘을 사용할때 vector 예시를 들수 있다.
(라운드-로빈 알고리즘은 OS 프로세스 스케줄러인데, 시간 순서대로 할당하다가 마지막 프로세스가 끝나면 다시 첫 프로세스로 돌아가서 시간을 할당하는 방식으로 작동한다)
라운드-로빈은 반복자를 사용해서 리스트 끝에 원소를 추가하고, 끝에 다하면 다시 처음으로 돌아가는 내용이 포함된다.
이때 라운드-로빈을 template으로 제작하고, 해당 T를 vector<T>를 가지는 클래스로 제작하면 반복자를 사용해서 구현하기 편하다.
1. RoundRobin클래스를 정의하고, process는 작업클래스로, scheduler를 관리클래스로 제작한다.
2. scheduler의 멤버변수로 RoundRobin<Process> 를 정의한다.
3. 여러개의 process를 제작한다음, roundrobin<process>에 추가한다.
4. scheduler가 가지고 있는 roundrobin을 실행하면, roundrobin내에서 원소들(vector<process>)이 순차적으로 실행한다.
deque
vector와 거의 비슷하지만 활용도가 낮다.
원소리를 vector와 다르게 메모리에 연속적으로 저장하지 않는다.
많이 사용하지 않는다.
list
이중 연결 리스트를 구현한 표준 라이브러리 클래스 템플릿이다.
그렇기 때문에 front()와 back()만 알수 있다. (operator[] 로 못가져온다)
나머지 원소들은 반복자로만 접근이 가능하다.
대부분 vector와 비슷하다.
- splice()
통째로 다른 리스트에 이어붙이기 기능이다.
대체로 list보다는 vector가 빠르다.
forward_list
단방향 리스트로, 한 방향으로만 반복할 수 있다.
array
크기가 고정된 점을 제외하면 vector와 같다. (array는 크기를 늘리거나 줄일수 없다)
vector처럼 프리스토어에 저장해서 접근하지 않고, 원소를 스택에 할당하기 위해서 크기를 고정시켜 놓는것이다.
span
연속 객체 순차열을 참조하는 객체이다.
연속 객체 순차열을 사용해야 하거나 확장이 필요할때 다양한 오버로딩을 하지않고 사용할 수 있다.
void print(span<const int> values)
{
for (const auto& value : values) {
cout << value << " ";
}
cout << endl;
}
int main()
{
vector v{ 11, 22, 33, 44, 55, 66 };
print(v); //11, 22, 33, 44, 55, 66}:
span mySpan{ v };
print(mySpan); //11, 22, 33, 44, 55, 66}:
span subspan{ mySpan.subspan(2, 3) }; //스팬의 하위 범위를 가져온다.
print(subspan); //33, 44, 55
print({ v.data() + 2, 3 }); //33, 44, 55
array<int, 5> arr{ 5, 4, 3, 2, 1 };
print(arr); // 5, 4, 3, 2, 1
print({ arr.data() + 2, 3 }); // 3 2 1
int carr[]{ 9, 8, 7, 6, 5 };
print(carr); // C 스타일 배열 전체
print({ carr + 2, 3 }); // c 스타일 배열의 서브류
}
queue
컨테이너 어댑터로서 FIFO방식으로 구현되었다.
컴퓨터에 도달한 패킷을 순서대로 처리하기 위해서 queue를 많이 사용한다.
priority_queue (우선순위 큐)
엄격한 FIFO 방식대신에 맨 앞에 있는 원소의 우선순위가 가장 높다.
우선순위 큐는 에러 상관관계를 고려해서 가장 중요한 에러부터 먼저 처리하게 할 때 많이 사용된다.
Stack
queue와 많이 비슷하며, 다른점은 FILO방식이라는 것이다.
스택은 에러 상관관계를 고려하지 않고 가장 최근에 발생한 에러를 띄우도록 처리할 때 많이 사용된다.
pair
두 값을 그룹으로 묶는 클래스 템플릿이다.
public 데이터 멤버로써 first와 second로 각각 접근이 가능하다.
map
key값 기준으로 sorting된다.
이진 탐색트리로 구현되었기 때문에 unordered_map보다 value를 찾는 데에 오래걸릴 수 있다.
단일값 대시에 키와 값의 쌍으로 저장한다.
정렬 및 비정렬 연관 컨테이너를 흔히 노드 기반 데이터 구조라 부른다.
은행 계좌를 사용할때 map을 사용한다.
multimap
한 키에 여러 값을 담을 수 있는 map이다.
친구목록을 사용할때 사용한다.
set
map과 비슷하며, 키/값 쌍으로 저장하지 않고, 키가 값이라는 점이 다르다.
set은 키가 없고 정보를 중복되지 않게 정렬해서 저장하고 추가, 조회, 삭제 연산도 빠르게 처리하고 싶을때 적합하다.
set은 값을 키/값을 변경할 수 없다. 순서가 바뀔 수 있기 때문이다.
접근 권한 관리를 할때 사용한다. (데이터가 유일하다는 점을 이용해서 데이터 비교, 확인에 용이하다)
multiset
map과 multimap의 관계처럼 여러개의 데이터를 담을 수 있다.
key값이 중복이 가능하다.
비정렬 연관 컨테이너는 해시테이블이라고도 부른다.
앞에 unordered가 붙으며, 이들은 모두 해시값을 통해서 찾는다.
이 해시값은 찾고자 하는 key값을 해시함수로 여과를 통해 해시값을 도출해낸다. 이 해시값으로 버킷에 접근하고,
이 버킷에에서 찾은 해시값과 비교해 결과값을 찾아내는 방식이다.
이때 만약 해시함수로 여과할때 같은 해시값이 도출된다면 문제가 발생한다(hash collision)
이를 해결하기 위해서 이차 함수 재해싱, 리니어 체이닝같은 다양한 방식이 있다.
unordered_map
중복이 허용되며 map보다 더 빠르게 값을 찾는다(해시값을 통해 찾기 때문에 더 빠르다)
unordered_multimap
unordered_set
unordered_multiset
그 외 컨테이너
bitset
고정된 크기의 비트열을 추상화한 것이다.
정식 표준 라이브러리가 아니며 크기가 고정되어있꼬, 원소 타입에 대해 템플릿화 할수 없다. 또, 반복자또한 제공하지 않는다.
19. 함수 포인터, 함수 객체, 람다 표현식
함수에게도 엄연한 주소가 부여된다.
함수에 대한 타입 앨리어스를 정의하면 변수처럼 메소드에서 호출할 수 있다.
using Matcher = bool(*)(int, int);
using MatchHandler = void(*)(size_t, int, int);
void findMatches(span<const int> values1, span<const int> values2,
Matcher matcher, MatchHandler handler)
{
if (values1.size() != values2.size()) { return; } // Both vectors must be same size.
for (size_t i{ 0 }; i < values1.size(); ++i) {
if (matcher(values1[i], values2[i])) {
handler(i, values1[i], values2[i]);
}
}
}
bool intEqual(int item1, int item2)
{
return item1 == item2;
}
bool bothOdd(int item1, int item2)
{
return item1 % 2 == 1 && item2 % 2 == 1;
}
void printMatch(size_t position, int value1, int value2)
{
cout << format("Match found at position {} ({}, {})",
position, value1, value2) << endl;
}
int main()
{
vector values1{ 2, 5, 6, 9, 10, 1, 1 };
vector values2{ 4, 4, 2, 9, 0, 3, 1 };
cout << "Calling findMatches() using intEqual():" << endl;
findMatches(values1, values2, intEqual, printMatch);
cout << "Calling findMatches() using bothOdd():" << endl;
findMatches(values1, values2, bothOdd, printMatch);
}
코드에서 보면 타입 앨리어스에서 정의한 Matcher와 MatchHandler가 호출된 것을 볼 수 있다.
클래스가 가지고있는 데이터 멤버와 메서드도 이와같은 방식으로 사용할 수 있다.
{
// Old style:
//int (Employee::*methodPtr) () const { &Employee::getSalary };
// Using a type alias:
//using PtrToGet = int (Employee::*) () const;
//PtrToGet methodPtr{ &Employee::getSalary };
// Using auto:
auto methodPtr{ &Employee::getSalary };
Employee employee{ "John", "Doe" };
cout << (employee.*methodPtr)() << endl;
}
{
int (Employee::*methodPtr) () const { &Employee::getSalary };
Employee* employee{ new Employee{ "John", "Doe"} };
cout << (employee->*methodPtr)() << endl;
delete employee;
}Employee라는 클래스에는 int값을 반환하는 getSalary() 가 있다.
이를 methodPtr이라고 불리는 타입 앨리어스를 정의하고 이를 사용한 예이다.
std::function
위와 같은 방식으로 함수 포인터를 대체할수 있는 std::function을 이용해서 정의할 수 있다.
다형성 함수 래퍼라고도 부른다.
using Matcher = function<bool(int, int)>;
using MatchHandler = function<void(size_t, int, int)>;
... 아래 동일
함수 객체
어떤 클래스의 함수 호출 연산자를 오버로드해서 그 클래스의 객체를 함수 포인터처럼 사용하게 만들수 있다.
이를 함수 객체, 또는 펑터라고 부른다.
template<typename Matcher, typename MatchHandler>
void findMatches(span<const int> values1, span<const int> values2,
Matcher matcher, MatchHandler handler)
{
if (values1.size() != values2.size()) { return; } // Both vectors must be same size.
for (size_t i{ 0 }; i < values1.size(); ++i) {
if (matcher(values1[i], values2[i])) {
handler(i, values1[i], values2[i]);
}
}
}
void printMatch(size_t position, int value1, int value2)
{
cout << format("Match found at position {} ({}, {})",
position, value1, value2) << endl;
}
class IsLargerThan
{
public:
explicit IsLargerThan(int value) : m_value{ value } {}
bool operator()(int value1, int value2) const { //함수 객체에 사용될 호출 연산자
return value1 > m_value && value2 > m_value;
}
private:
int m_value;
};
int main()
{
vector values1{ 2, 500, 6, 9, 10, 101, 1 };
vector values2{ 4, 4, 2, 9, 0, 300, 1 };
findMatches(values1, values2, IsLargerThan{ 100 }, printMatch);
}
산술함수 객체
C++는 다섯가지 이항 산술 연산자인 plus, minus, multiplies, divides, modulus에 대한 펑터 클래스 템플릿을 제공한다.
template<typename Iter, typename StartValue, typename Operation>
auto accumulateData(Iter begin, Iter end, StartValue startValue, Operation op)
{
auto accumulated{ startValue };
for (Iter iter{ begin }; iter != end; ++iter) {
accumulated = op(accumulated, *iter);
}
return accumulated;
}
double geometricMean(span<const int> values)
{
auto mult{ accumulateData(cbegin(values), cend(values), 1, multiplies<int>{}) };
return pow(mult, 1.0 / values.size());
}
위 예시는 multiplies라는 펑터 클래스 템플릿을 사용해서 제작한 코드이다.
투명 연산자 펑터
multiplies<int>{} 를 multiplies<>{} 로 사용가능하다.
이 투명 연산자 펑터의 장점은 코드가 간결할 뿐만 아니라 이종 타입을 지원해서 실제 기능도 뛰어나다.
비교 함수 객체
모든 표준비교연산(equal_to, not_equal_to, less, greater, less_equal, greater_equal)을 펑터로 사용할 수 있다.
priority_queue<int, vector<int>, greater<>> myQueue;
논리 함수 객체
비교 연산자들(logical_not, logical_and, logical_or)을 펑터로 사용할 수 있다.
accumulateData(begin(flags), end(flags), true, logical_and<>{});
비트 연산 함수 객체
비트 연산자들(bit_and, bit_or, bit_xor, bit_not)을 펑터로 사용할 수 있다.
어댑터 함수 객체
함수 객체가 내 요구사항에 딱 맞지 않을 수 있는데, 이럴때는 어댑터 함수 객체를 사용하여 둘 사이의 간극을 줄일 수 있다. 이러한 어댑터들은 함수 합성을 지원한다.
바인더
콜러블의 매개변수를 일정한 값으로 묶을 수 있다.
bind 뒤에 사용하고자 하는 함수와 다음에 올 매개변수가 몇번째 변수를 뜻하는지, 어떤 변수를 사용할 것인지를 미리 정의할 수 있다.
void func(int num, string_view str)
{
cout << format("func({}, {})", num, str) << endl;
}
int main()
{
string myString{ "abc" };
auto f1{ bind(func, placeholders::_1, myString) }; //func의 str매개변수는 myString으로 고정
f1(16);
auto f2{ bind(func, placeholders::_2, placeholders::_1) }; //순서 바꿈
f2("Test", 32);
}만약 바인더를 사용할때 오버로드로 정의된 함수가 존재한다면 에러가 발생할 것이다.
이때, 확실하게 바인드하려고 하는 함수를 지정해줘야 하는데 방법은 다음과 같다.
void overloaded(int /* num */) {}
void overloaded(float /* f */) {}
...
// Bind overloaded function
//auto f3{ bind(overloaded, placeholders::_1) }; // ERROR
auto f4{ bind((void(*)(float))overloaded, placeholders::_1) }; // OK
ref() 와 cref()
functional에 정의된 헬퍼 템플릿 함수
void increment(int& value)
{
++value;
}
int main()
{
int index{ 0 };
increment(index);
auto incr1{ bind(increment, index) };
incr1();
auto incr2{ bind(increment, ref(index)) };
incr2();
}위와 같은 방식으로 단순하게 index를 넘기면 복사본에 대한 레퍼런스가 사용되기 때문에 실제 index값이 변경되지 않는다. 이때 bind에서 ref()로 제퍼런스를 제대로 지정하면 index값이 변경되는 것을 확인할 수 있다.
부정 연산자
바인더와 비슷하지만 콜러블의 결과를 반전시킨다는 점이 다르다.
findMatches(values1, values2, not_fn(intEqual), printMatch);intEqual은 받은 2개의 int매개 변수값이 같은지 비교하는 함수이다.
not_fn 을 사용하면 결과를 반전시키기 때문에 값이 다를때만 true로 반환된다.
람다
위와 같이 어댑터와 펑터를 사용하면 많이 복잡해진다.
따라서 가능하다면 람다를 활용하여 코드를 간결하고 깨끗하게 코딩을 해야 한다.
람다는 익명함수를 뜻한다.
람다는 람다 선언자(람다 소개자)라 부르는 대괄호 로 시작하고, 그 뒤에 람다 표현식의 본문을 담는 중괄호{}가 나온다.
auto basicLambda{ [] { cout << "Hello from Lambda" << endl; } };
basicLambda();컴파일러는 모든 람다 표현식을 자동으로 함수 객체로 변환한다. 이를 람다 클로저라 부르며, 컴파일러가 생성한 고유 이름을 갖는다.
람다에게 파라미터가 존재하는 경우 소괄호를 붙여서 사용한다.
auto parametersLambda{ [](int value) { cout << "The value is " << value << endl; } };
parametersLambda(42);람다에게 리턴을 표기할 수 있는데 이때 트레일링 리턴 타입이라 불리는 화살표로 표기하고, 이를 생략해도 된다.
컴파일러가 함수 리턴 타입 추론 규칙에 따라 람다 표현식의 리턴 타입을 추론하기 때문이다.
auto returningLambda{ [](int a, int b) -> int { return a + b; } };
int sum{ returningLambda(11, 22) };
cout << "The result is " << sum << endl;
auto returningLambda2{ [](int a, int b) { return a + b; } };
sum = returningLambda2(11, 22);
cout << "The result is " << sum << endl;자동으로 추론하게 될 경우와 지정하게 되는 경우는 결과가 다르게 나온다.
아래 코드에선 위에선 자동 추론이라 string값, 즉 복제본이 나오게 된다.
그 아래 코드에선 -> decltype(auto) 로 지정함으로써 const string& 값으로 지정해서 받게 된다.
Person p{ "John Doe" };
decltype(auto) name1{ [](const Person& person) { return person.getName(); }(p) };
decltype(auto) name2{ [](const Person& person) -> decltype(auto) { return person.getName(); }(p) };대괄호 부분을 람다 캡처블록이라 부르는데, 변수를 캡쳐한다는 말은 상위 스코프에서 변수를 가져와 람다 표현식의 본문에서 사용할 수 있게 만든다는 뜻이다.
double data{ 1.23 };
auto capturingVLambda{ [data] { cout << "Data = " << data << endl; } };
capturingVLambda();위와 같은 방식과 마찬가지로 mutable 이란 키워드를 사용하면 값을 복사하게 되어서 람다 밖에 있는 변수엔 영향을 받지 못한다. 하지만 반대로 레퍼런스값(&)으로 가져오게 될 경우엔 밖의 변수도 영향을 받게 된다.
auto capturingVLambda2{ [data]() mutable { data *= 2; cout << "Data = " << data << endl; } };
capturingVLambda2();
auto capturingRLambda{ [&data] { data *= 2; } };
capturingRLambda();캡쳐할 변수를 고르거나, 디폴트로 정의할 수 있다.
[=] : 스코프에 있는 변수 모두를 값으로 캡쳐
[&] : 스코프에 있는 변수 모두를 레퍼런스로 캡쳐
[&x] : x만 레퍼런스로 캡쳐
[=, &x] : x만 레퍼런스로 캡쳐하고 외 모두는 값으로 캡쳐
[this] : 현재 객체를 캡쳐
[*this] : 현재 객체의 복제본을 캡쳐. 람다 표현식을 실행하는 시점에 객체가 살아 있지 않을 경우에 유용하다.
...
이제 펑터를 람다로 바꾸면 다음과 같다.
이때 람다를 명시적으로 표현식을 호출하고자 하는 findMatches내에 직접 작성할 수 있다.
auto areEqual{ [](const auto& value1, const auto& value2) { return value1 == value2; } };
vector values1{ 2, 5, 6, 9, 10, 1, 1 };
vector values2{ 4, 4, 2, 9, 0, 3, 1 };
findMatches(values1, values2, areEqual, printMatch);
invoke
일반 함수, 람다, 멤버 함수를 호출할 때 사용한다.
이는 임의의 콜러블을 호출하는 템플릿 코드를 작성할 때는 유용하게 쓰인다.
void printMessage(string_view message)
{
cout << message << endl;
}
int main()
{
invoke(printMessage, "Hello invoke.");
invoke([](const auto& msg) { cout << msg << endl; }, "Hello invoke.");
string msg{ "Hello invoke." };
cout << invoke(&string::size, msg) << endl;
}
20. 표준 라이브러리 알고리즘 완전 정복
find()
주어진 반복자 범위에서 특정한 원소를 검색한다.
if (auto it{ find(cbegin(myVector), endIt, number) }; it == endIt) {
cout << "Could not find " << number << endl;
}
find_if()
인수로 검색할 원소가 아닌 프레디케이트 함수 콜백을 받는다는 점을 제외하면 find()와 같다.
(프레디케이트 함수 콜백 - true나 false를 리턴하는 함수 콜백)
accumulate()
컨테이너에 있는 원소를 모두 더하는 산술 연산 알고리즘.
double sum{ accumulate(cbegin(values), cend(values), 0.0) };
// accumulate(first, last, initValue, calculate)
// 시작 / 끝 / 초기값 / 연산방식(람다 가능)
알고리즘 콜백
알고리즘은 펑터나 람다 표현식 등으로 주어진 콜백에 대해 복제본을 여러개 만들어서 다양한 원소에 대해 별도로 호출해 줄 수 있다.
auto isPerfectScore{ [tally = 0] (int i) mutable {
cout << ++tally << endl; return i >= 100; } };
auto endIt{ cend(myVector) };
auto it{ find_if(cbegin(myVector), endIt, isPerfectScore) };
if (it != endIt) { cout << "Found a \"perfect\" score of " << *it << endl; }
isPerfectScore(1); //별도 출력myVector에 1,2,3 만 들어있다고 가정한다면 결과값은 1,2,3 이 출력되고 별도로 람다를 호출해서 1이 추가로 출력된다.
즉, find_if 알고리즘에 의해서 콜백에 대한 복제본을 만들고 가져가기 때문에 알고리즘 내에선 데이터를 공유하고 파기된다.
만약 복제본이 아닌 값을 가져게 하기 위해선 ref()를 감싸면된다.
//auto it{ find_if(cbegin(myVector), endIt, isPerfectScore) };
auto it{ find_if(cbegin(myVector), endIt, ref(isPerfectScore)) };이렇게 했을때 출력값은 1,2,3,4 가 나오게 된다.
불변형 순차 알고리즘
주어진 원소를 검색하거나 두 범위를 서로 비교하는 함수. 개수를 세는 집계도 여기에 포함된다.
- 탐색 알고리즘
find_if_not(start , end, 조건) : 조건에 만족하지 않는 첫번째 원소 검색
adjacent_find(start, end) : 같은 값이 연속된 첫 번째 원소 쌍
find_first_of(start, end, target start, target end) : 두 값중 첫번째 값
search(start, end, target start, target end) : 첫 번째 부분열
find_end(start, end, target start, target end) : 마지막 부분열
search_n(start, end, 반복 수, target) : target이 반복 수만큼 연속된 첫번째 부분열
-특수 탐색 알고리즘
search알고리즘에 원하는 탐색 알고리즘을 옵션으로 지정할 수 있도록 매개변수가 추가되었다.
default_searcher
boyer_moore_searcher
boyer_moore_horspool_searcher
boyer_moore_searcher searcher{ cbegin(toSearchFor), cend(toSearchFor) };
- 비교 알고리즘
equal() : 주어진 원소가 모두 같은 경우 true
mismatch() : 주어진 범위에서 일치하지 않는 범위를 가리키는 반복자를 리턴
lexicographical_compare() : 제공된 두 범위에서 동일한 위치에 있는 원소를 서로 비교
- 집계 알고리즘
all_of() : 모든 변수가 조건에 맞는 경우
any_of() : 조건에 맞는 변수가 있는 경우
none_of() : 조건에 맞는 변수가 없는 경우
count() : 조건에 맞는 변수 갯수 카운트
count_if() : 조건에 맞는 변수 갯수가 조건에 맞는지 체크
- 가변형 순차 알고리즘
한 범위에 있는 원소를 다른 범위로 복제하거나, 원소를 삭제하거나, 주어진 범위의 원소 순서를 반대로 바꿀수 있다.
가변형 알고리즘 중 일부는 원본과 대상 범위를 모두 지정한다.
generate() : 반복자 범위를 인수로 받아서 그 범위에 있는값을 세번째 인수로 지정한 함수의 리턴값으로 교체한다.
transform() : 범위를 받고 4번째 인수로 지정한 함수 리턴값을 3번째 인수 위치에서 부터 값을 변경한다.
copy() : 주어진 범위에 있는 원소를 다른 범위로 복제한다.
move() : 주어진 범위에 있는 원소를 이동시킨다.
replace() : 주어진 범위에서 값이나 프레디케이트로 지정한 조건에 일치하는 원소를 새 값으로 교체한다.
erase() : C++20에 추가된 내용이다. 인자로 지정한 값과 일치하는 원소를 모두 삭제한다. 이때, 반복자 범위가 아닌 컨테이너에 대한 레퍼런스를 사용한다)
remove() : erase보다 비효율적인 방법으로, 지원하는 컨테이너에서만 사용이 가능하다. vector가 그 예인데, vector에서 메모리를 연속적으로 사용하기 때문에 연속적인 상태를 유지하도록 신경쓰면서 삭제해야 한다. remove는 진짜로 없애는 것이 아니고 삭제되어야 할 원소들의 위치에 유지될 원소들의 값을 덮어 씌우는 방식이라 진짜 없애는 것은 아니다. 이 문제를 제거후 삭제패턴을 통해 해결한다.
unique() : 같은 원소가 연달아 나오는 부분을 모두 삭제한다.
shuffle() : 주어진 범위 원소를 무작위 순으로 재정렬한다.
sample() : 지정한 원본 범위의 원소를 무작위 n개 골라 리턴한다.
reverse() : 주어진 범위에 있는 원소의 순서를 반대로 바꾼다.
shift() : C++20에 추가된 내용이다. 주어진 범위 원소를 새로운 위치로 이동시키는 방식의 함수이다.
- 연산 알고리즘
for_each() : 주어진 범위에 있는 원소마다 콜백으로 실행한다.
for_each_n() : 주어진 범위에 n번째 원소까지 콜백으로 실행한다.
- 분할 알고리즘
partition_copy() : 원본에 있는 원소를 복제해서 서로 다른 두 대상으로 분할한다. 이때, 둘 중 어느 대상에 원소를 보낼지는 프레디케이트의 실행 결과가 true 인지 false인지에 따라 달라진다.
- 정렬 알고리즘
담긴 원소가 특정한 조건을 기준으로 순서에 맞게 유지하도록 재배치한다.
sort() : 주어진 범위에 있는 원소를 O (N log N)시간에 정렬한다.
stable_sort() : 주어진 범위에서 같은 원소에 대해서는 원본에 나온 순서를 그대로 유지한다. sort()보다 성능은 떨어진다.
nth_element() : (선택 알고리즘) 원소 범위에 있는 n번째 원소에 대한 반복자를 받아서 반복자가 가리키는 n번째 위치에 있는 원소가 전체 범위를 정렬한 후 그 위치에 있도록 주어진 범위를 제정렬한다.
- 이진 탐색 알고리즘
정렬된 시퀀스만 적용하거나, 검색 대상을 기준으로 분할된 시퀀스만 적용하는 이진 탐색 알고리즘이 있다.
binary_search() : 이진 탐색 속도는 선형 시간보다 빠른 로그 시간이다.
lower_bound() : 정렬된 범위에서 주어진 값보다 작지 않은 원소중에서 첫 번째를 찾아낸다. (upper_bound, equal_range)
- 집합 알고리즘
includes() : 부분 집합을 판별하는 알고리즘. 정렬된 두 범위중에서 한쪽의 원소가 다른쪽 범위에 모두 포함되는지 검사한다. 순서는 고려하지 않는다.
set_union() : 합집합
set_intersection() : 교집합
set_difference() : 차집합
set_symmetric_difference() : 대칭차집합
merge() : 정렬된 두 범위를 하나로 합칠 수 있다.
- 최대/최소 알고리즘
min() , max()
- 병렬 알고리즘
성능 향상을 위해 병렬 처리 알고리즘들이 있는데, for_each, all_of, copy, count_if, find, replace, search, sort, transform 등이 있다.
병렬 실행하는 알고리즘은 소위 실행 정책이라 부르는 옵션을 첫 번째 매개변수로 받는다. 이러한 실행 정책을 이용해서 주어진 알고리즘을 병렬로 실행할지 아니면 벡터 방식으로 순차 처리할지 결정한다.
sort(execution::par, begin(myVector), end(myVector));실행 방식이 par 이라면 병렬로 실행한다는 뜻이다.
- 수치 처리 알고리즘
iota : 주어진 범위에서 지정한 값부터 시작해서 operation++로 값을 순차적으로 생성한다.
- 리듀스 알고리즘
accumulate, reduce, inner_product, transform_reduce가 있고, 주어진 범위 또는 두개 범위에 있는 원소를 결합하는 연산을 값 하나만 남을때 까지 반복한다.
reduce() : 벡터원소들의 합을 구하는 accumulate와 동일한 기능이다. accumulate는 병렬이 안되고, reduce는 가능하다.
inner_product() : 두 벡터의 내적을 구한다.
transform_reduce() : 병렬 실행을 지원하며 범위 하나 또는 두 개에 대해 실행할 수 있다. 마찬가지로 원소의 합을 구한다.
- 스캔 알고리즘
주어진 범위에 대해 적용된 알고리즘의 결과는 원본 범위의 원소에 대한 합을 담은 또 다른 범위가 된다.
partial_sum() : 요소들의 합을 구한다. 0번째엔 첫번째 값. 1번째엔 첫번째 + 두번째값. 2번째엔 첫+두+셋 ...
exclusive_scan() : 요소들의 구간합을 구하는데, 끝부분을 포함하지 않는다.
inclusive_scan() : 요소들의 구간합을 구하는데, 끝부분을 포함한다.
transform_exclusive_scan() : 요소들을 먼저 변환한 후 구간 합을 구하는데, 끝부분을 포함하지 않는다.
transform_inclusive_scan() : 요소들을 먼저 변환한 후 구간 합을 구하는데, 끝부분을 포함한다.
21. 스트링 현지화와 정규 표현식
진짜 좋은 프로그램은 전 세계적으로 사용된다. 따라서, 프로그램을 작성할땐 현지화(로컬라이제이션)을 지원하거나 로케일을 인식하도록 처리할 수 있게 설계하는것이 가장 좋다.
현지화의 가장 중요한 원칙은 소스코드에 특정 언어로 된 스트링을 넣으면 안된다는 것이다.
loadResource() : 주어진 이름으로 스트링 리소스를 불러온다.
로케일
특정한 데이터를 문화적 배경에 따라 그룹으로 묶는 방식.
날짜 포맷, 시간 포맷, 숫자 포맷등으로 구성된다.
이러한 요소들을 패싯이라 부른다.
I/O 스트림을 사용할 때 데이터 포맷은 특정한 로케일에 맞춰져 있따. 이때, POSIX 표준에서는 언어와 지역을 두 글자로 표현하고 그 뒤에 옵션으로 인코딩 방식을 붙여서 표현한다.
미국의 로케일은 en_US , 영국은 en_GB, 한국은 ko_KR에 유닉스 확장 완성형 인코딩은 euc_KR, UTF-8은 utf8옵션을 붙여 표기한다.
imbue() : 사용자 환경에 설정된 로케일을 사용할 수 있도록 설정하는 메소드.
wcout.imbue(locale{ "" });
wcout << 32767 << endl;
wcout.imbue(locale{ "C" });
wcout << 32767 << endl;
wcout.imbue(locale{ "en-US" }); // "en_US" for POSIX
wcout << 32767 << endl;위의 값이 미국식 영어일때 32,767로 출력된다.
만약 네덜란드 벨기에라면 32.767이 출력된다.
디폴트 로케일은 사용자 로케일이 아니라 클래식/뉴트럴 로케일이다.
C가 클래식 로케일 미국식 영어 이지만, 약간의 차이가 있다.
C를 붙이면 32767로 출력된다.
en-US를 붙이면 32,767로 출력된다.
string 객체에 대해 find()를 호출하면 인수로 지정한 서브스트링을 검색할 수 있다. 지정한 서브스트링을 찾지 못한다면 npos를 리턴하는데, 이를 활용해서 현재 로케일을 알아 낼 수 있다.
locale loc{ "" };
if (loc.name().find("en_US") == string::npos &&
loc.name().find("en-US") == string::npos) {
wcout << L"Welcome non-US English speaker!" << endl;
} else {
wcout << L"Welcome US English speaker!" << endl;
}
글로벌 로케일
std::locale::global() : 현재 애플리케이션의 글로벌 C++로케일을 인수로 지정한 로케일로 교체한다.
locale::global(locale{ "en-US" }); // "en_US" for POSIX
문자 분류
isspace(), isblank(),isupper() 등과 같이 조건에 맞는 문자를 분류할 수 있다.
bool result{ isupper('É', locale{ "fr-FR" }) }; //true
문자 변환
toupper() 등과 같이 문자를 변경할 수 있다.
패싯 사용법
std::use_facet() : 특정한 로케일의 패싯을 구할 수 있다.
locale locUSEng{ "en-US" };
wstring dollars{ use_facet<moneypunct<wchar_t>>(locUSEng).curr_symbol() };moneypunct 는 화폐 금액에 대한 포매팅 매개변수를 정의하는 패킷이다.
변환
다양한 방식으로 인코딩된 문자를 쉽게 변환하도록 codecvt 라는 클래스 템플릿을 제공한다.
예) codecvt<char16_t, char, mbstate_t> : UTF-16과 UTF-8을 변환한다.
정규 표현식
<regex>에 정의되어 있는 기능으로, 스트링 처리에 특화된 기능이다.
검증 : 입력 스트링이 형식을 제대로 갖췄는가
판단 : 주어진 입력이 표현하는 대상을 확인한다
파싱 : 입력 스트링에서 정보를 추출한다.
변환 : 주어진 서브스트링을 검색해서 다른 스트링으로 교체한다.
반복 : 주어진 서브스트링이 나온 부분을 모두 찾는다.
토큰화 : 정해진 구분자를 기준으로 스트링을 나누다.
C++에서 지원하는 문법은 다음과 같다.
ECMAScript , basic, extended, awk, grep, egrep
ECMAScript
정규 표현식 패턴은 매치할 문자를 표현한다. 정규 표현식에서 다음과 같은 특수 문자를 제외한 나머지 문자는 표현식에 명시된 그대로 매치한다.
^ $ / . * + ? ( ) [ ] { } |
앵커
특수문자중 ^는 줄끝을 표현하는 문자의 바로 다음 지점을 가르키는 앵커, &는 줄끝을 표현하는 바로 그 지점을 가르키는 앵커로, 기본적으로 ^는 시작을, &는 끝을 가르킨다. ( ^test& 는 test란 스트링만 매치한다)
와일드 카드
. 은 줄바꿈 문자를 제외한 모든 문자를 매치한다.( a.c 는 abc 또는 a5c 를 매치한다)
선택 매치
| 는 '또는' 관계를 표현한다. (a|b 는 a나 b를 매치한다)
그룹화
소괄호는 부분 표현식 또는 캡처 그룹을 표현한다.
반복
다음과 같은 반복 문자를 활용하면 정규 표현식의 일부분을 반복 적용할 수 있다.
*는 그 앞에 나온 패턴을 0번이상 매치한다. (a*b 패턴은 b, ab, aab, aaaab 등을 매치)
+는 그 앞에 나온 패턴을 한번이상 매치한다. (a+b 패턴은 ab, aab, aaaab등을 매치. 단, b는 매치하지않음.)
?는 그 앞에 나온 패턴을 0번 또는 한번이상 매치한다. (a?b 패턴은 b, ab만 매치한다)
중괄호에 2숫자가 들어가는것은 반복횟수가 제한을 뜻한다. (a{n,m}은 a를 n번이상, m번 이하 반복한것을 매치. a{3,4} 라면 aaa, aaaa 를 매치. a 나 aaaaa 는 매치하지않음)
연산 우선순위
수학 연산처럼 정규 표현식에서도 우선순위가 있다. 순서는 다음과 같다.
원소 - 한정자(+, * ....의 앞에 붙은 원소) - 연결(+, * ....의 뒤에 붙은 원소) - 선택(|)
문자 집합 매치
문자를 일일이 명시하면 번거롭기 때문에 대괄호에 묶어서 문자 집합을 지정한다.
^는 뒤에 문제를 제외하고 찾는다. (ab[cde] : abc, abd, abe / ab[^cde] : abf, abp 등은 매치하지만 c,d,e가 붙으면 매치안함)
-를 표현해서 범위 지정이 가능하다 ([a-zA-Z] : a부터z, A부터Z) 이때 (-)를 매치하려면 이스케이프 시켜야 한다.
문자 클래스를 지정하는 방법으로 표현 범위를 지정할 수 있다(digit : 숫자, alpha : 알파벳 문자 등등)
단어 경계
첫번째 문자가, 숫자, 언더스코어와 같은 단어용 문자로 시작하면 스트링의 시작이다. 표준 C 로케일에선 [A-Za-z0-9_]에 해당된다.
원본 스트링의 첫 문자가 단어용 문자중 하나라면 원본 스트링의 시작이다.
원본 스트링의 끝 문자가 단어용 문자중 하나라면 원본 스트링의 끝이다.
단어의 끝 문자는 단어용 문자가 아니지만, 그 앞에 나온 문자는 단어용 문자이다.
백레페런스
정규 표현식안에 있는 캡처 그룹을 참조할 수 있다.
미리보기
정규 표현식은 ?= 패턴으로 표기하는 양의 미리보기와 ?! 패턴으로 표기하는 음의 미리보기를 지원한다.
양의 미리보기라면 지정한 패턴이 반드시 나와야 하고, 음의 미리보기라면 그 패턴이 나오지 않아야 한다.
정규 표현식과 로 스트링 리터럴
특수문자가 많이 등장하는데, 로 스트링 리터럴을 사용하면 정규 표현식을 더 쉽게 표현할 수 있다.
로 스트링 리터럴을 사용하면 이스케이프를 사용하지 않기 때문에 보기 편하다.
자주 쓰는 정규 표현식
패스워드나 전화번호, 날짜 등과 같이 흔히 사용하는 패턴에 대한 정규표현식은 새로 만들필요없이 웹에서 검색하면 쉽게 찾을 수 있다.
regex
정규 표현식 라이브러리에 관한 내용은 <regex>에 정의되어 있다.
basic_regex : 특정한 정규 표현식을 표현하는 객체
match_results : 정규 표현식에 매치된 서브스트링으로서 캡처 그룹을 모두 포함한다.
sub_match : 반복자와 입력 시퀀스에 대한 쌍을 담은 객체이다. 여기 나온 반복자는 매치된 캡처 그룹을 표현한다.
- regex_match
주어진 원본 스트링을 주어진 정규 표현식 패턴으로 비교한다.
regex r{ "\\d{4}/(?:0?[1-9]|1[0-2])/(?:0?[1-9]|[1-2][0-9]|3[0-1])" };
while (true) {
cout << "Enter a date (year/month/day) (q=quit): ";
string str;
if (!getline(cin, str) || str == "q") {
break;
}
if (regex_match(str, r)) {
cout << " Valid date." << endl;
} else {
cout << " Invalid date!" << endl;
}
}
- regex_search
부분 스트링도 찾고 싶은 경우에 사용한다. 한 부분이라도 일치한다면 true를 반환한다.
regex r{ "//\\s*(.+)$" };
while (true) {
cout << "Enter a string with optional code comments (q=quit): ";
string str;
if (!getline(cin, str) || str == "q") {
break;
}
if (smatch m; regex_search(str, m, r)) {
cout << format(" Found comment '{}'", m[1].str()) << endl;
} else {
cout << " No comment found!" << endl;
}
}
- regex_iterator
컨테이너에 대해 반복자와 비슷하게 작동한다. (sregex_iteractor는 string용 반복자)
regex reg{ "[\\w]+" };
while (true) {
cout << "Enter a string to split (q=quit): ";
string str;
if (!getline(cin, str) || str == "q") {
break;
}
const sregex_iterator end;
for (sregex_iterator iter{ cbegin(str), cend(str), reg }; iter != end; ++iter) {
cout << format("\"{}\"", (*iter)[0].str()) << endl;
}
}
- regex_token_iteractor
매치된 결과중에서 캡처 그룹 전체 또는 그중에서 선택된 캡처그룹에 대해서만 루프를 돌 수 있다.
이때 0번 인덱스에 접근않고 iter->str 로 했는데, 이는 모든 캡처 그룹에 대해 자동으로 반복하기 때문이다.
regex reg{ "[\\w]+" };
while (true) {
cout << "Enter a string to split (q=quit): ";
string str;
if (!getline(cin, str) || str == "q") {
break;
}
const sregex_token_iterator end;
for (sregex_token_iterator iter{ cbegin(str), cend(str), reg };
iter != end; ++iter) {
cout << format("\"{}\"", iter->str()) << endl;
}
}
- regex_token_iteractor는 필드 분할작업에도 활용된다.
-1은 regex_token_iteractor 생성자에서 반복할 캡처 그룹 인덱스를 토큰화 모드로 작동한다는 뜻이다.
토큰화 모드는 시퀀스에서 주어진 정규 표현식에 대해 매치되지 않은 모든 서브스트링에 대해 반복된다.
regex reg{ R"(\s*[,;]\s*)" };
while (true) {
cout << "Enter a string to split on ',' and ';' (q=quit): ";
string str;
if (!getline(cin, str) || str == "q") {
break;
}
const sregex_token_iterator end;
for (sregex_token_iterator iter{ cbegin(str), cend(str), reg, -1 };
iter != end; ++iter) {
cout << format("\"{}\"", iter->str()) << endl;
}
}
- regex_replace
정규 표현식과 매치된 서브스트링을 대체할 포맷 스트링을 인수로 받는다.
const string str{ "<body><h1>Header</h1><p>Some text</p></body>" };
regex r{ "<h1>(.*)</h1><p>(.*)</p>" };
const string replacement{ "H1=$1 and P=$2" };
string result{ regex_replace(str, r, replacement) };
cout << format("Original string: '{}'", str) << endl;
cout << format("New string : '{}'", result) << endl;regex_replace는 플래그에 맞춰 작동 방식을 변경할 수 있다.
format_default : 디폴트. 매치되는 항목 모두 교체. 매치되지 않은 항목 모두 출력에 복제.
format_no_copy : 매치되는 항목을 모두 교체하지만 매치되지 않는 부분은 출력에 복제하지 않는다.
format_first_only : 패턴에 첫 번째로 매치되는 항목만 교체한다.
22. 날짜와 시간 유틸리티
Ratio 라이브러리를 이용하면 컴파일 시간에 정확히 표현할 수 있다.
using r1 = ratio<1, 60>;
intmax_t num{ r1::num };
intmax_t den{ r1::den };
cout << format("1) r1 = {}/{}", num, den) << endl; //1/60
using r2 = ratio<1, 30>;
cout << format("2) r2 = {}/{}", r2::num, r2::den) << endl; //1/30
using result = ratio_add<r1, r2>::type;
cout << format("3) sum = {}/{}", result::num, result::den) << endl; //1/20
using res = ratio_less<r2, r1>;
cout << format("4) r2 < r1: {}", res::value) << endl; // r2 < r1 : falsenum은 분자이고 den은 분모이다. 분자와 분모가 컴파일 시간에 결정이 된다는 뜻이다.
duration
틱과 틱 주기값을 저장한다.
clock
현재 시각을 time_point로 리턴한다.
time_point
시간의 시작점을 표현하는 에포크를 기준으로 측정한 기간(duration)으로 저장한다.
time_point<steady_clock> tp1;
tp1 += minutes{ 10 };
auto d1{ tp1.time_since_epoch() };
duration<double> d2{ d1 };
cout << d2.count() << " seconds" << endl;
23. 무작위수 기능
무작위수 엔진
random_device , linear_congruential_engine , mersenne_twister_engine , subtract_with_carry_engine
무작위수 발생기의 성능은 무질서도(엔트로피)로 측정한다.
random_device rnd;
cout << "Entropy: " << rnd.entropy() << endl;
cout << "Min value: " << rnd.min()
<< ", Max value: " << rnd.max() << endl;
cout << "Random number: " << rnd() << endl;
무작위수 생성하기
엔진을 인스턴스를 진행한 후에 추출해야 한다.
random_device seeder;
const auto seed{ seeder.entropy() ? seeder() : time(nullptr) };
mt19937 engine{ static_cast<mt19937::result_type>(seed) };
uniform_int_distribution<int> distribution{ 1, 99 };
auto generator{ bind(distribution, engine) };
vector<int> values(10);
generate(begin(values), end(values), generator);
for (auto i : values) {
cout << i << " ";
}
cout << endl;
24. 기타 라이브러리 유틸리티
variant
주어진 타입 집합중에서 어느 한 타입의 값을 가진다.
variant<int, string, float> v;
v = 12;
v = 12.5f;
v = "An std::string"s;한 타입만 가지기 때문에 v는 결국 마지막 string값을 취하게 된다.
이땐 비지터 패턴(방문자 패턴)을 적용해서 적합한 값이 호출되는 것을 확인하면 된다.
class MyVisitor
{
public:
void operator()(int i) { cout << "int " << i << endl; }
void operator()(const string& s) { cout << "string " << s << endl; }
void operator()(float f) { cout << "float " << f << endl; }
};
...
visit(MyVisitor{}, v); //string An std::string
...std::visit을 활용해서 저장된 적합한 값으로 호출된 것이다.
any
값 하나를 모든 타입으로 저장할 수 있는 클래스다.
만약 값을 가져오려고 할땐 any_cast<type>으로 가져와야 한다.
any empty;
any anInt{ 3 };
cout << "empty.has_value = " << empty.has_value() << endl; //0
cout << "anInt.has_value = " << anInt.has_value() << endl << endl; //1
cout << "anInt wrapped type = " << anInt.type().name() << endl; //int
int theInt{ any_cast<int>(anInt) };
cout << theInt << endl; //3
tuple
tuple은 pair를 일반화한 클래스다. tuple은 2개 이상의 값을 쌍으로 가질 수 있다.
using MyTuple = tuple<int, string, bool>;
MyTuple t1{ 16, "Test", true };
cout << format("t1 = ({}, {}, {})", get<0>(t1), get<1>(t1), get<2>(t1)) << endl;
tuple을 구조적 바인딩으로 분리가 가능하다.
tuple t1{ 16, "Test"s, true }; // Using CTAD
auto [i, str, b] { t1 };
cout << format("Decomposed: i = {}, str = \"{}\", b = {}", i, str, b) << endl;
tuple을 std::tie()를 이용해서 분리가 가능하다
int i{0};
bool b{false};
tie(i, ignore, b) = t1;만약 필요없는 원소가 있다면 std::ignore를 적으면 된다.
연결
std::tuple_cat() 을 이용해서 두 tuple을 하나로 연결할 수 있다.
tuple t1{ 16, "Test"s, true }; // Using CTAD
tuple t2{ 3.14, "string 2"s };
auto t3{ tuple_cat(t1, t2) };
비교
비교연산자가 지원되기 때문에 사용 가능하다.
tuple t1{ 123, "def"s }; // Using CTAD.
tuple t2{ 123, "abc"s };
if (t1 < t2) {
cout << "t1 < t2" << endl;
} else {
cout << "t1 >= t2" << endl;
}
//t1 >= t2
이렇게 많은 타입이 늘어단다면 모든 operator< 를 구현하는게 쉽지 않을 것이다.
<=> 를 이용한다면 더 쉽게 구현이 가능하다.
auto operator<=>(const Foo& rhs)
{
return tie(m_int, m_str, m_bool) <=>
tie(rhs.m_int, rhs.m_str, rhs.m_bool);
}
make_from_tuple
튜플로부터 클래스 객체를 만들때 보통 사용된다.
class Foo
{
public:
Foo(string str, int i) : m_str{ move(str) }, m_int{ i } {}
private:
string m_str;
int m_int;
};
int main()
{
tuple myTuple{ "Hello world.", 42 };
auto foo{ make_from_tuple<Foo>(myTuple) };
}
apply
std::apply()는 콜러블(함수, 람다 표현식, 함수 객체)를 호출하는데 이때 지정한 tuple의 원소를 인수로 전달한다.
int add(int a, int b)
{
return a + b;
}
int main()
{
cout << apply(add, tuple{ 39, 3 }) << endl;
}
'Book > 전문가를 위한 C++20' 카테고리의 다른 글
| 전문가를 위한 C++20 _ 5 (C++ 소프트웨어 공학) (1) | 2024.03.24 |
|---|---|
| 전문가를 위한 C++20 _ 4 (C++ 고급 기능 마스터하기) (0) | 2024.03.24 |
| 전문가를 위한 C++20 _ 2 (전문가다운 C++ 소프트웨어 설계 방법) (1) | 2024.03.22 |
| 전문가를 위한 C++20 _ 1 (C++와 표준 라이브러리 초단기 속성 코스) (1) | 2024.03.21 |