
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 구글 컨퍼런스
- 리팩터링
- 스즈메의 문단속
- 스포일러 주의
- 상계9동
- 언리얼 5
- shader
- 전주비빔 라이스 버거
- 2023 게이밍 인 구글 클라우드
- 2023 Gaming
- 이득우의 언리얼 프로그래밍1
- 2023 게이밍
- 공부
- 1일차
- 주식
- 이득우의 언리얼 프로그래밍 1
- URP
- JavaScript
- 리팩터링 3장
- 2023 구글 클라우드
- 448일선
- unity
- 리팩터링 4장
- 산토리 하이볼
- 주식단테
- 언리얼5
- GenAI
- 224일선
- 112일선
- 작계훈련
- Today
- Total
개발 이야기 안하는 개발자
전문가를 위한 C++20 _ 1 (C++와 표준 라이브러리 초단기 속성 코스) 본문
1. C++ 기초
import <iostream>;
int main()
{
std::cout << "Hello, World!" << std::endl;
return 0;
}C++20 이전 버전에선 #include <iostream>이런 방식의 전처리 지시자로 사용해야 했다.
하지만 20으로 넘어오면서 모듈을 임포트하도록 변경되었다.
20부터 새로 생긴 기능인 이 모듈은 예전의 헤더파일과 같은 메커니즘이다. (완전히 대체함)
이스케이프 시퀀스 (탈출/이탈 문자열)
\n - 줄바꿈
\r - 커서를 맨 앞으로
\t - 탭
\\ - 역슬래시
네임 스페이스
코드에서 이름이 서로 충돌하는 문제를 해결하기 위해 나온 개념. (using 지시자로 접두어 생략 가능)
스코프
변수에 접근할 수 있는 범위
스코프 지정 연산자 (범위 지정 연산자 - :: )
범위에서 사용된 식별자(identifier)를 식별하고 구분하는데 사용
namespace mycode
{
void foo()
{
std::cout << "foo() called in the mycode namespace" << std::endl;
}
}
using namespace mycode;
int main()
{
mycode::foo(); // Calls the "foo" function in the "mycode" namespace
foo(); // implies mycode::foo();
}
네임 스페이스 앨리어스
이름을 다르게 만들거나 짧게 만들 수 있음
namespace MyFTP = MyLibr::Networking::FTP;
숫자 경계값
max / min / lowest 등이 있음
cout << format("Max int value: {}\n", numeric_limits<int>::max()); // Max int value : 2147483647
캐스트 (형변환)
float myFloat{ 3.14f };
int i1{ (int)myFloat }; // method 1
int i2{ int(myFloat) }; // method 2
int i3{ static_cast<int>(myFloat) }; // method 3
short someShort{ 16 };
long someLong{ someShort }; // no explicit cast needed
강타입 열거
일반 열겨형은 상위 스코프에서 이름을 그대로 사용할 수 있다.
여기서 생기는 문제는 같은 이름이 있으면 컴파일 에러가 발생한다는 것이다.
bool ok {false};
enum Status {error, ok}; // ok가 이름이 중복되어 에러 발생강타입 열거형은 위와 같은 문제가 발생하지 않는다.
열거형을 선언할때 enum이 아닌 enum class로 선언한다.
구조체
모듈 인터페이스 파일에 구조체로 정의하며, 파일의 확장자는 .cppm이다.
C++20으로 오면서 모든 모듈은 익스포트를 해야 한다.
모듈을 employee로 export 했다면, 사용하는 쪽에선 import를 employee로 받아야 한다.
//employee.cppm
export module employee;
export struct Employee {
char firstInitial;
char lastInitial;
int employeeNumber;
int salary;
};
//main.cpp
import <format>;
import employee;
int main()
{
// create and populate an employee
Employee anEmployee;
anEmployee.firstInitial = 'J';
...
함수
모든 함수는 내부적으로 __func__라는 로컬 변수로 정의되어 현재 함수의 이름을 담고있다.
int addNumbers(int number1, int number2)
{
cout << format("Entering function {}", __func__) << endl;
return number1 + number2;
}
array
고정 크기 컨테이너. C에선 배열을 사용했지만 C++에선 array컨테이너를 쓰는게 더 효율적이다.
항상 크기를 정확히 알 수 있꼬, 자동으로 포인터를 캐스트(동적 형변환)하지 않아서 특정한 종류의 버그를 방지할 수 있고, 반복자로 배열에 대한 반복문을 쉽게 작성할 수 있다.
int myArray[]{ 1, 2, 3, 4 }; // C Array
array<int, 3> arr{ 9, 8, 7 }; // C++ array
CTAD
클래스 탬플릿 인수 추론 (class templace argument deduction)이란 사용자가 정의하는 템플릿 인자를 자동 추론해주는 기능이다. C++는 해당기능을 지원한다.
array arr {9, 8 ,7}; //CTAD가 해당 array는 array<int, 3> 이라는것을 자동으로 안다.
vector
크기가 고정되지 않은 컨테이너. 벡터도 CTAD를 지원하기 때문에 vector myVector {11, 22}; 로 써도 된다.
vector<int> myVector{ 11, 22 };
// vector myVector { 11, 22 }; // CTAD
myVector.push_back(33);
myVector.push_back(44);
cout << format("1st element: {}", myVector[0]) << endl;
pair
두 값을 하나로 묶는다.
pair<double, int> myPair{ 1.23, 5 };
// pair myPair { 1.23, 5 }; // CTAD
cout << format("{} {}", myPair.first, myPair.second);
optional
타입의 값을 가질수 있고, 아무값도 가지지 않을 수도 있다. (null)
has_value() 메서드를 사용하거나 if문으로 값이 담겨있는지 체크해서 사용한다.
값이 있다면 value()나 역참조 연산자로 그 값을 가져올 수 있다.
optional<int> getData(bool giveIt)
{
if (giveIt) {
return 42;
}
return nullopt; // 또는 return {};
}
int main()
{
optional<int> data1{ getData(true) };
optional<int> data2{ getData(false) };
cout << "data1.has_value = " << data1.has_value() << endl;
if (data2) {
cout << "data2 has a value." << endl;
}
cout << "data1.value = " << data1.value() << endl;
cout << "data1.value = " << *data1 << endl;
try {
cout << "data2.value = " << data2.value() << endl;
} catch (const bad_optional_access& ex) {
cout << "Exception: " << ex.what() << endl;
}
cout << "data2.value = " << data2.value_or(0) << endl;
}
구조적 바인딩
array, struct, pair등에 원소들을 한꺼번에 초기화가 가능하다.
std::array values{ 11, 22, 33 };
auto [x, y, z] { values };
struct Point { double m_x, m_y, m_z; };
Point point;
point.m_x = 1.0; point.m_y = 2.0; point.m_z = 3.0;
auto [x, y, z] { point };
초기자 리스트
여러 인수를 받는 함수를 쉽게 작성할 수 있다.
int makeSum(initializer_list<int> values)
{
...
}
int main()
{
int a{ makeSum({ 1, 2, 3 }) };
int b{ makeSum({ 10, 20, 30, 40, 50, 60 }) };
...
}
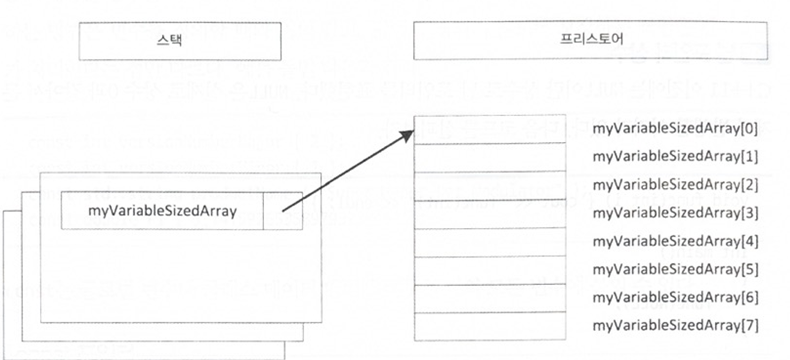
스택과 프리스토어
스택은 프로그램의 현재 스코프를 표현하며 주로 현재 실행 중인 함수를 가르킨다.
이러한 함수들은 계속 쌓이며(스택 프레임이 쌓인다) 최상단에서 현재 실행중인 함수를 가르킨다.
예를들어 foo() 가 호출되고, 스코프내에서 bar()를 호출하면 bar 스택 프레임은 foo위에 올라온다.
스택은 각 함수가 독립된 메모리 공간에 제공되어 foo()함수 내에 정의된 변수는 bar()가 실행되더라도 수정하지 않으면 해당 변수는 삭제되거나 변경되지 않는다.
또 함수가 종료되어 스택 프레임이 삭제된다면 해당 변수도 릴리즈되기 때문에 따로 삭제할 필요 없다.
프리 스토어는 함수, 스택프레임과는 완전히 독립적인 메모리 공간이다.
함수가 끝난 후에도 변수를 계속 유지하고 싶다면 프리 스토어에 저장하면 되는데, 이는 사용이 끝나면 직접 할당 해제를 해야 한다.
힙은 malloc과 free로 의해 할당 해제가 되며, 프리 스토어는 new와 delete로 할당 해제가 된다.
포인터
int* myIntPointer { nullptr }위 포인터는 정수 타입에 대한 메모리 공간을 가르킨다는 것을 의미한다. 지금은 가르키는 대상이 없고, 부울 표현식에서는 false취급한다.
해당 포인터가 가르키는 값에 접근하려면 포인터를 역참조를 해야 한다. (프리스토어에 있는 실제 값을 가르키는 화살표를 따라간다)
*myIntPointer = 8;
myIntPointer = 8 은 메모리 주소가 8인 지점을 가르키는 것이고,
*myIntPointer = 8은 메로리 주소로 가르키는 값을 8로 할당하는 것이다.
할당 해제는 아래와 같이 진행한다.
delete myIntPointer;
myIntPointer = nullptr;
포인터는 프리스토어뿐만 아니라 스택과 같은 다른 종류의 메모리를 가르킬 수 있다.
레퍼런스(참조) 연산자인 &를 사용하면 된다.
int i { 8 };
int* myIntPointer {&i};
동적으로 배열을 할당할때도 프리스토어를 활용한다. new 연산자가 프리스토어에 할당한다고 보면 된다.
정수 타입 원소만큼의 메모리가 할당되고, 스택에 있는 myVariableSizedArray는 프리스토어에 있는 배열을 가르킨다.
int arraySize{ 8 };
int* myVariableSizedArray{ new int[arraySize] };
myVariableSizedArray[3] = 2;
delete[] myVariableSizedArray;
myVariableSizedArray = nullptr;
상수 (const)
실행되는 동안 변경되지 않을 값
const int* ip; //int const* ip;
ip = new int[10];
// ip[4] = 5; // DOES NOT COMPILE!포인터와 가르키는 값 모두를 const로 지정하고 싶다면 아래와 같이 작성한다.
int const* const ip{ nullptr }; //const int* const ip{ nullptr };
메서드에 const를 붙이면 해당 메서드 내에서 멤버변수를 수정할 수 없다.
constexpr로 정의된 메서드에서는 const를 수정할 수 있다.
레퍼런스 변수
변수뒤에 &를 붙이면 해당 변수를 레퍼런스 변수가 된다.
int x{ 3 };
int& xRef{ x };
xRef = 10;변수 x와 레퍼런스 변수 xRef는 모두 같은 값을 가르킨다.
즉, xRef는 x의 또다른 이름이라고 볼 수 있다.
매개변수는 값 전달 방식(pass-by-value)을 따르기 때문에 값을 수정한다고 해서 원본은 수정되 않는다.
이때 레퍼런스 값을 넘기면 (pass-by-reference) 원본이 넘어가기 때문에 값이 수정된다.
void addOneA(int i)
{
i++;
}
void addOneB(int& i)
{
i++;
}
void swap(int& first, int& second)
{
int temp{ first };
first = second;
second = temp;
}
int main()
{
int myInt{ 7 };
addOneA(myInt); //원본 수정 안됨
addOneB(myInt); //원본 수정 됨
int x{ 5 }, y{ 6 };
swap(x, y);
// swap(3, 4); //리터럴 값을 넣으면 컴파일이 되지 않는다.)
int* xp{ &x }, * yp{ &y };
swap(*xp, *yp);
}
RVO, NRVO
RVO는 return value optimization 의 줄인말이고, 함수에 대한 매개변수거나, 임싯값일때 적용된다.
값을 돌려줄때(반환할때) 객체에 대해 할당된 메모리에 직접 넣어 초기화 해주는 기능을 뜻하는데, 이는 컴파일러가 자동으로 해준다.
함수에서 결과값을 반환할때 결과값을 복사해서 반환을 해주는데, 이때 불필요한 복사 행위를 줄이기 위해 사용되는 기능이라고 보면 된다.
RVO는 이러한 복사 행위가 일어날 것같은 곳에 복사하지 않고 직접 데이터를 넣어 초기화 한다.
NRVO는 named return value optimization의 줄인말이고 변수명에도 RVO가 적용된다는 것이다.
타입 앨리어스
기존에 선언된 타입에 다른 이름을 붙이는 것.
과거엔 typedef 를 사용했었고, 지금도 사용가능하지만 코드의 가독성이 떨어진다.
using IntPtr = int *;
//typedef int* IntPtr;
int* p1;
IntPtr p2;
auto 키워드
auto는 컴파일 시간에 타입을 자동으로 추론할 변수 앞에 붙인다.
이 auto는 타입이 길거나 복잡할때 사용하면 편리하다.
const도 지원하고, 레퍼런스도 지원한다. 포인터도 적용이 가능하다.
auto x {123}; //x는 int 타입
복제 리스트 초기화와 직접 리스트 초기화도 auto로 가능하다.
T obj = {arg1 , arg2 , ...}; //복제 리스트 초기화
T obj {arg1 , arg2 , ...}; //직접 리스트 초기화
decltype 키워드
인수로 전단한 표현식의 타입을 알아낸다.
int x {123};
decltype(x) y {456};y의 타입이 x의 타입인 int라고 추론한다.
2. 스트링과 스트링뷰 다루기
스트링 리터럴
변수에 담지 않고 바로 값으로 표현하는 스트링
읽기전용 영역에 저장되어 스트링 리러털을 여러번 작성해도 컴파일러는 실제 메모리 공간은 딱 하나만 할당하는데, 이를 리터럴 풀링이라 한다.
cout << "hello" << endl; //이때 "hello"가 스트링 리터럴
로 스트링 리터럴
이스케이프 시퀀스를 표현하지 않고 바로 적용된다. 또한 이스케이프 시퀀스를 적는다고 해도 그대로 출력된다.
const char* str5{ R"(Line 1
Line 2)" };단, 로 스트링 리터럴은 소괄호로 문장을 끝내기 때문에 소괄호를 넣으면 에러가 발생한다.
스트링 CTAD
vector names {"AAA" , "BBB" , "CCC"};위와 같이 코드를 작성하면 vector<string> 이 아닌 vector<const char*> 로 추론한다. 이런 코드는 정상 작동하지 않거나 뻗어버린다. 이를 위해서 string 리터럴로 지정해야 하는데, 각 스트링 리터럴 끝에 s를 붙인다.
vector names {"AAA"s , "BBB"s , "CCC"s};
string_view
const string& 대신 사용할 수 있으며 오버헤드도 없다. 즉, 스트링을 복사하지 않는다.
string_view는 읽기전용 스트링이며 string과 기능적으로 비슷하다.
읽기전용이기 때문에 수정이 불가능하다.
사용을 위해선 .data()를 써야 한다.
스트링뷰 리터럴
예시 = "6"sv
포맷 지정자
출력할 때 적용할 포맷을 설정한다. 포맷 지정자는 앞에 콜론(:)이 붙으며, 일바적으론 다음과 같은 형식으로 표기한다.
대괄호 안에 있는 모든 부분은 선택사항이다.
[[fill]align][sign][#][0][width][.precision][type]
width - 주어진 값의 포맷을 적용할 필드의 최소 폭을 설정한다.
[fill]align - 채울 문자와 해당 필드에 값이 정렬되는 방식을 지정한다. (< 왼쪽 정렬, > 오른쪽 정렬, ^가운데 정렬)
sign - (-) 음수에만 부호를 붙인다, (+) 음수 양수 모두 부모를 붙인다, (space) 음수에는 마이너스, 양수에는 빈칸이 붙는다.
# - 얼티네이트 포매팅 규칙 제공. 0b(이진수), 0(8진수), 0x(16진수)를 표시한다.
type - 반드시 따라야 할 타입을 지정한다.
precision - 부동소수점과 스트링타입에만 적용되며, 점 뒤에 문자 개수를 지정한다 (동적 정밀도)
0 - width로 지정한 최소 폭에 맞게 0을 집어넣는다.
{
// width
int i{ 42 };
cout << format("|{:5}|", i) << endl; // | 42|
cout << format("|{:{}}|", i, 7) << endl; // | 42|
}
cout << endl;
{
// [fill]align
int i{ 42 };
cout << format("|{:7}|", i) << endl; // | 42|
cout << format("|{:<7}|", i) << endl; // |42 |
cout << format("|{:_>7}|", i) << endl; // |_____42|
cout << format("|{:_^7}|", i) << endl; // |__42___|
}
cout << endl;
{
// sign
int i{ 42 };
cout << format("|{:<5}|", i) << endl; // |42 |
cout << format("|{:<+5}|", i) << endl; // |+42 |
cout << format("|{:< 5}|", i) << endl; // | 42 |
cout << format("|{:< 5}|", -i) << endl; // |-42 |
}
cout << endl;
{
// Integral types
int i{ 42 };
cout << format("|{:10d}|", i) << endl; // | 42|
cout << format("|{:10b}|", i) << endl; // | 101010|
cout << format("|{:#10b}|", i) << endl; // | 0b101010|
cout << format("|{:10X}|", i) << endl; // | 2A|
cout << format("|{:#10X}|", i) << endl; // | 0X2A|
}
cout << endl;
{
// String types
string s{ "ProCpp" };
cout << format("|{:_^10}|", s) << endl; // |__ProCpp__|
}
cout << endl;
{
// Floating-point types
double d{ 3.1415 / 2.3 };
cout << format("|{:12g}|", d) << endl; // | 1.365870|
cout << format("|{:12.2}|", d) << endl; // | 1.37|
cout << format("|{:12e}|", d) << endl; // |1.365870e+00|
int width{ 12 };
int precision{ 3 };
cout << format("|{2:{0}.{1}f}|", width, precision, d) << endl; // | 1.366|
}
cout << endl;
{
// 0
int i{ 42 };
cout << format("|{:06d}|", i) << endl; // |000042|
cout << format("|{:+06d}|", i) << endl; // |+00042|
cout << format("|{:06X}|", i) << endl; // |00002A|
cout << format("|{:#06X}|", i) << endl; // |0X002A|
}
3. 코딩 스타일
바람직한 코드 작성 스타일의 기준을 정확히 제시하기 쉽지 않다.
그럼에도 잘 작성된 코드에서 볼 수 있는 공통적인 속성이 있다.
- 문서화
- 코드 분해
- 명명규칙
- 언어 사용
- 코드 서식(포매팅)
문서화
소스 파일에 주석을 다는 것.
- 사용법을 알려주는 주석 (메소드 사용법 , 리턴 값 , 익셉션 등등) - 하지만 혼자 할땐 축소하는 것을 추천
- 복잡한 코드를 설명하는 주석
- 메타 정보를 제공하는 주석 (작성자 , 작성일 등등)
- 문장단위로 작성하거나 너무 많이 작성하면 가독성이 떨어지기 때문에 적당히 해야한다.
- 가장 좋은건 조금의 주석으로 충분히 설명 가능한 잘 작성된 코드
코드 분해
코드를 더 작은 단위로 나눠서 작성하는 방식 (함수나 메서드마다 한가지 작업만 하는 것)
- 정해진 단위는 없지만 적당히 나눌것.
- 리팩터링을 통한 코드 분해
- 추상화 (필드 캡슐화 - private을 설정 , gettor settor 로 접근하게 / 타입 일반화 - 좀더 일반적인 타입을 사용)
- 논리적으로 분해 (메서드 추출 - 이해하기 쉽게 일부를 추출 / 클래스 추출 - 기존 클래스를 새 클래스로 분해)
- 명칭과 위치를 개선 (메서드 및 필드 옮기기 - 더 적합한 클래스나 소스코드로 이동 / 메서드 및 필드 이름 바꾸기 - 목적이 잘 들어나도록 이름 변경 / 올리기 - 기본(parent) 클래스로 옮기기 / 내리기 - 상속(child) 클래스로 옮기기)
명명 규칙
변수, 메서드, 함수 등의 이름으로 그 용도가 명확히 드러나야 한다.
언어 사용
가독성이 좋은 코드를 작성해야 한다.
- 상수 사용하기
- 포인터 대신 레퍼런스 사용하기
- 포인터보다 더 안전하다. (메모리 주소를 직접 다루지 않고, nullptr 이 될 수 없기 때문에)
코드 서식
한 프로젝트에서 한 코드서식을 지정해야 코드의 가독성이 올라간다.
- 중괄호 정렬 문제
- 스페이스 소괄호 논쟁
- 스페이스 , 탭 , 줄바꿈 문제
'Book > 전문가를 위한 C++20' 카테고리의 다른 글
| 전문가를 위한 C++20 _ 5 (C++ 소프트웨어 공학) (1) | 2024.03.24 |
|---|---|
| 전문가를 위한 C++20 _ 4 (C++ 고급 기능 마스터하기) (0) | 2024.03.24 |
| 전문가를 위한 C++20 _ 3 (전문가답게 C++ 코딩하기) (2) | 2024.03.23 |
| 전문가를 위한 C++20 _ 2 (전문가다운 C++ 소프트웨어 설계 방법) (1) | 2024.03.22 |
